


Why is Everyone Training Very Deep Neural Network with Skip Connections?
Importance of Skip Connections in Deep Neural Networks

Deep neural networks (DNNs) have are a powerful means to train models on various learning tasks, with the capability to automatically learn relevant features. According to empirical studies, there seem to be positive correlation between model depth and generalization performance.
Generally, training PlainNets (Neural networks without Skip Connections) with few number of layers (i.e. typically one to ten layers) is not problematic. But when model depth is increased beyond 10 layers, training difficulty can experienced. Training difficulty typically worsens with increase in depth, and sometimes even the training set cannot be fitted. For example, when training from scratch there was optimization failure for the VGG-13 model with 13 layers and VGG-16 model with 16 layers. Hence, VGG-13 model was trained by initializing its first 11 layers with the weights of the already trained VGG-11 model. Similar was the case with VGG-16. Currently, there is proliferation of networks, such as Resnet, FractalNet, etc which use skip connections.
What are skip connections?
Skip connections are where the outputs of preceding layers are connected (e.g. via summation or concatenation) to later layers. Architectures with more than 15 layers have increasingly turned to skip connections. According to empirical studies, skip connections alleviate training problems and improve model generalization. Although multiple weights initialization schemes and batch normalization can alleviate the training problems, optimizing PlainNets becomes absolutely impossible beyond a certain depth.
Experimental Results
Experiments were done on MNIST, CIFAR-10 and CIFAR-100 datasets using PlainNet, ResNet and ResNeXt, each having 164 layers.

Tables 1, 2, 3 & 4 show the obtained accuracies on the different datasets. Clearly it can be seen, as in figure 3 and figure 4, that PlainNets perform worser than networks with skip connections and are essentially untrainable. PlainNets failure to learn, given the very poor accuracies on the training sets.

Discussion and Observations:
The plot of PlainNets activations and weights given below in Figure 5 and Figure 6.


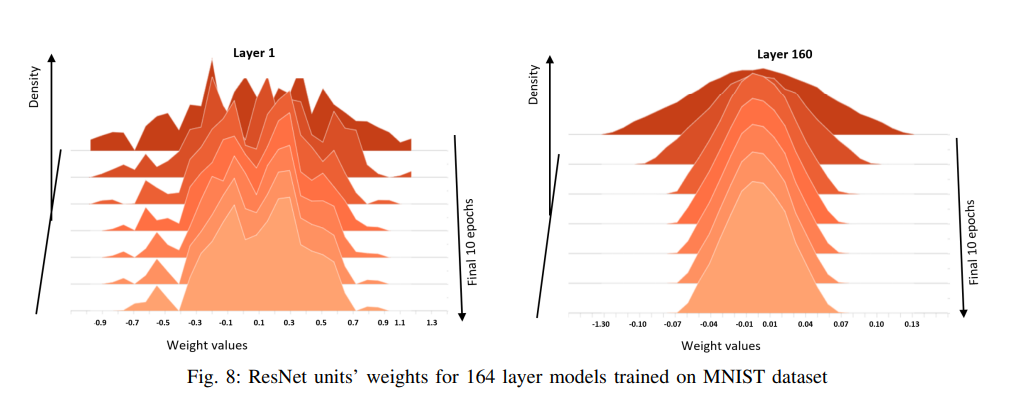
The plot of ResNet unit’s activations and weights given below in Figure 7 and Figure 8.

According to authors of the paper, “the PlainNet trained on CIFAR10 dataset, starting from the eightieth layer, have hidden representations with infinite condition numbers; on CIFAR100 dataset, starting from the hundredth layer, the PlainNet’s hidden representations have infinite condition numbers. This observation depicts the worst scenario of the singularity problem for optimization such that model generalization is impossible as given in Remark 8. In contrast, the hidden representations of the ResNet never have infinite condition numbers; the condition numbers, which are high in the early layers quickly reduce to reasonable values so that optimization converges successfully.”
Conclusion
Skip connections are a powerful means to train Deep Neural Networks.
Subscribe to receive a copy of our newsletter directly delivered to your inbox.
The above article is sponsored by Vevesta.
Vevesta: Your Machine Learning Team’s Collective Wiki: Identify and use relevant machine learning projects, features and techniques.
100 early birds who login into Vevesta will get free subscription for 3 months