
Plateau Problem: Why is stopping the neural network early is not always the best option?
Plateaus complicate our decision on where to stop the gradient drop

We’ve all noticed that after a certain number of steps of training a neural network, the loss begins to slow significantly. After a long period of constant loss, the loss may suddenly resume dropping rapidly for no apparent reason, and this process will repeat until we run out of steps.
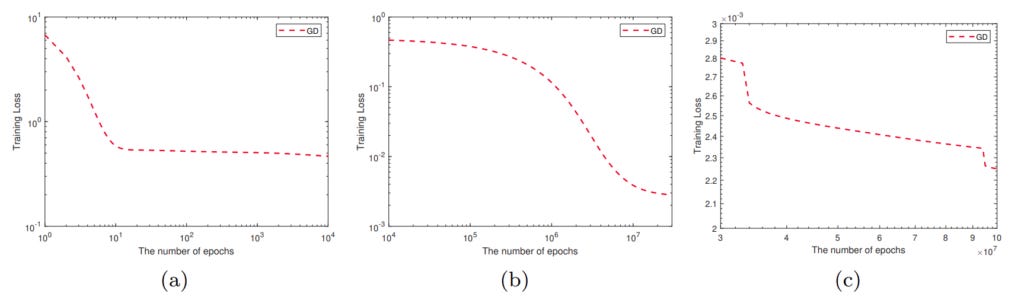
Figure (a) shows that the loss decreases dramatically for the first ten epochs, but then tends to remain constant for a long time. Thereafter the loss tends to fall dramatically, as shown in figure (b), and then becomes nearly constant.
Many of us may base our decision on the curve shown in fig (a), but the fact is that if we train our network for more epochs, there is a chance that the model will converge at a better point.
These plateaus complicate our decision on where to stop the gradient drop and also slow down convergence because traversing a plateau with the hope of decreasing the loss requires a greater number of iterations.
Cause of Plateau
There are two main causes due to which the formation of plateau takes place and they are as follows:
Saddle Point
Local Minima

Saddle Point

The main issue with saddle points is that the gradient is zero at the saddle point of a particular function, which does not represent the maximum and minimum value. The machine learning and optimization algorithms in a neural network are optimized by the gradient status, and if the gradient is zero, the model becomes stuck.
Local Minima

The point in this case is an extremum, which is excellent, but the gradient is zero. If our learning rate is too low, we may not be able to escape the local minimum. As shown in fig(a), the loss value in our hypothetical training situation began balancing around some constant number; one important reason for this is the formation of these types of local minimums.
Effect of Learning Rate
The learning rate hyperparameter controls how fast the model learns. While a higher learning rate allows the model to learn more quickly, it may result in a less-than-ideal final set of weights. A slower learning rate, on the other hand, may allow the model to acquire a more optimal, or possibly a globally optimal, set of weights, but it will take much longer to train. The issue with a slow learning rate is that it may never converge or become stuck on a suboptimal solution.
Thus, learning rate is important in overcoming the plateau phenomenon; techniques such as scheduling the learning rate or cyclical learning rate are used for this.
Methods to Overcome a Plateau Problem
The following approaches could be used to adjust learning rates in order to overcome the plateau problem:
Scheduling the Learning Rate
The most common approach is to schedule the learning rate, which proposes starting with a relatively high learning rate and gradually decreasing it during training. The idea is that we want to quickly get from the initial parameters to a range of excellent parameter values, but we also want a low enough learning rate to explore the deeper, but narrower, regions of the loss function.

Step decay is an example of this, in which the learning rate is reduced by a certain percentage after a certain number of training epochs.
Cyclical Learning Rate
Leslie Smith proposed a cyclical learning rate scheduling method with two fluctuating bound values.
The cyclical learning scheme strikes an exquisite balance between passing over local minima and allowing us to look around in detail.

Thus, scheduling the learning rate aids us in overcoming the plateau issues encountered while optimising neural networks.
Credits:
The above article is sponsored by Vevesta.
Vevesta: Your Machine Learning Team’s Collective Wiki: Identify and use relevant machine learning projects, features and techniques
100 early birds who login to Vevesta get free subscription for 3 months.
Subscribe to our weekly newsletter to stay updated on latest machine learning/MLOps articles.