
How to apply Boosting when the Data Labels are Noisy and Uncertain ?
LocalBoost - Local Boosting for Weakly-Supervised Learning

I blog about latest machine learning research topics that have an immediate impact on the work us data scientists/machine learning engineers do every day. Share the newsletter with your friends so that we all grow together.

Introduction
Boosting uses ensemble as a means to enhance performance of the model. A large number of boosting algorithms exist, starting from AdaBoost to the ever so popular XGBoost. But these algorithms suffers from a likely handicap that boosting is typically used when the data labels are accurate [1].
In real world applications, it is increasingly clear that many a times the processes used to label data, do not generate accurate clean data. It then becomes a non trivial task to design ensembles when the data is noisy and weak. This is where WSL (Weakly supervised learning) have started gaining attention. ‘WSL leverages weak supervision signals to generate a large amount of weakly labeled data, which is easier to obtain than complete annotations’[1]. But it has been found that state-of-the-art WSL methods still underperform fully-supervised methods by an average performance discrepancy is 18.84%, measured by accuracy or F1 score [1].
Challenges with apply Boosting to weak and noisy labels

As shown in Figure 1, if we apply supervised boosting methods while using weakly labeled dataset, we observe that the weight assigned to the initial base model is rather large such that it dominates the ensemble model prediction. This phenomenon is called “weight domination” by the authors of the LocalBoost [1].
A key challenge of adapting boosting methods to the weakly supervised learning(WSL) setting is to accurately compute the importance of each example in the weakly labeled training data for each base learner. However, when the labels are noisy and weak, accurate identification of error instances is a hinderance and thus authors [1] believe that we need to shift our focus from the label space to the training data.
Deeper Look at Local Boost
In the context of WSL, where most of the data are labeled by weak sources and only a limited number of data points have accurate labels. Authors[1] have introduced a novel iterative and adaptive framework for WSL boosting - Local Boost.
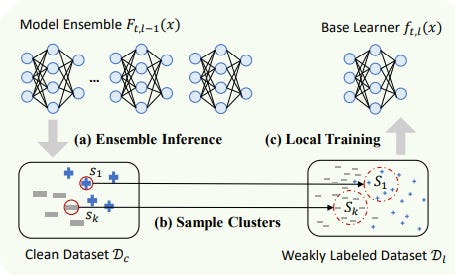
In the Figure 2, we observe that the clean data set Dc is used to identify instances s1,s2…sk. These instances are then used to identify clusters in the weakly labeled and noisy dataset Dl. The base learner then learns on these clusters. An important thing to note is that clean dataset influences clustering, but does not play a direct role in training the model.

As a next step ,as illustrated in Figure 3, authors[1] propose an estimate-then-modify paradigm for the model weights computation, in which a large number of weak labels are leveraged for the weight estimate, then the limited clean labels are used to rectify the estimated weight.
In particular, authors[1] first follow the AdaBoost procedure to estimate the weight 𝛼_𝑡,𝑙 on the weakly labeled dataset D_l. Merely using the noisy weak labels can hardly guarantee the boosting progress due to the fact that calculating error rates involves weak labels, which are less unreliable and can negatively affect the weight estimation. To address this issue, we further calibrate such estimated weights using the small clean dataset D𝑐 with a perturbation-based approach. In this approach, we add gaussian perturbation to the weights, and choose the perturbation that have the least validation error on the clean data set, Dc.
Results
Table 1 below gives the results achieved on implementation of Local Boost.
