


Learn from Experiences of Experts - Running Trustworthy A/B Test
The definitive practical guide to A/B tests summarizing experience of experts


I blog about latest machine learning research topics that have an immediate impact on the work us data scientists/machine learning engineers do every day. Share the newsletter with your friends so that we all grow together.
Introduction
Online controlled experiments (OCE) are digital versions of the traditionally known offline experiments i.e. randomized controlled Trials (RCT). The more commonly used term for OCE is A/B tests.
Some OCEs that have entered the folklore of the community are:
‘41 Shades of Blue’ by Google where 41 colors of blue were tested against each other on the search page and which led to $200 million increase in revenue [1].
Based on insights of OCE, Amazon moved credit card offers from the homepage to the checkout page. This resulted in Amazon earning tens of millions (USD) in profit annually [1].
Microsoft earned addition $100 million in USA alone based on OCE that optimized the way the advertisements were structured on Bing [1].
Given the above successes and the evidence that ‘more than 50% of ideas fail to generate meaningful improvements’ [1], the movement to A/B test ideas has only gathered steam over the last decade.
Overview of A/B Tests
Defining some terms that would aid in understanding the concept of OCE:
Overall Evaluation Criteria (OEC)/Performance Metric: OEC can be defined as a qualitative metric that measures the performance (i.e. success or failure) of the experiment. A good performance metric/OEC should not be short term, example clicks, revenue, etc. but should instead focus on long term customer value such as CLTV, repeat visits which measure stickiness of the user to the experience and hence, also the continued value the business can gets from the user. (PS: The value the business gets from the user is function of user experience and more broadly, the ‘value’ user gets from the product).
Guardrail Metrics: Business aligned metrics that are used to track any adverse effect of A/B tests. Guard rails protect the business from sudden deterioration of user experience, system performance, customer churn, etc. These are metrics which are relevant to business and are not captured in the metric being optimized for in the A/B test.
P-value: Ron Kohavi et al [2] define it as “The p-value is the probability of obtaining a result equal to or more extreme than what was observed, assuming that all the modeling assumptions, including the null hypothesis, H0, are true”. In probabilistic terms, we have the following formulation:
p-value = P(Δ Observed or more extreme|H0 is true)Confidence: The probability of failing to reject Null Hypothesis when its true.
Power: The probability of correctly rejecting the Null Hypothesis when its false. Power is a measure of ability to detect differences between the control and test, when they exist.
Effect ": Effect is defined as
mean of Performance metric in Treatment - mean of performance metric in controlFalse Positive Risk: One useful metric to look at is the ‘False Positive Risk (FPR), which is the probability that the statistically significant result is a false positive, or the probability that H0 is true (no real effect) when the test is statistically significant’ [2].
Estimating Statistical Power: Statistical Power is defined by authors [2] as ‘the probability of detecting a meaningful difference between the variants when there really is one, that is, rejecting the null when there is a true difference of δ.
With an industry standard power of 80%, and p-value threshold of 0.05, the sample size for each of two equally sized variants can be determined by this simple formula’:
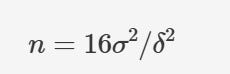
where
nis the number of users in each variant, and the variants are assumed to be of equal size, squaredσis the variance of the metric of interest, andδis the sensitivity, or the minimum amount of change you want to detect. Example: When at least 10% relative change is expected in the experiment and historically the value of the metric being tracked, say conversion is 3.7%. Then the variant size needed is 41,642.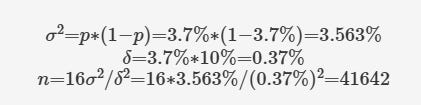
Commonly used values: Generally experiments are conducted with power as 80 (i.e. β : type-II error = 0.2 for 80% power) and α, the threshold used to determine statistical significance (SS), as equal to 0.05 for two-tailed test.

Practices for executing Trustworthy experiments
Size of Variants: According to Kohavi et al [2], ‘the general guidance is that A/B tests are useful to detect effects of reasonable magnitudes when you have, at least, thousands of active users, preferably tens of thousands’.
Avoid mis-interpretation of p-value and usage of “confidence”: A common mistake is to mistake p value of 0.05 as 5% probability of the A/B test result being a false positive. Also, a term confidence defined as:
confidence = (1-p_value) * 100It is often misinterpreted as the probability that the A/B test result is a true positive. Also, the authors [2] impress upon the need to invoke Twyman’s law, that is - any figure that looks interesting or different is usually wrong. When the result of an experiment is highly unusual or surprising and only accept the result if the p-value is very low.
Early Peeking : Sometimes users peek at the data in real time as the test is running and stop the test when it was statistically significant. This type of testing significantly inflates the type-I error rates [2].
A/A Test or Null Test: Among many reasons, A/A test test must be done to filter out the cases when the split between the two same variants is not along the expected ratio. This identifies the cases when there is some implementation bug in splitting the users during randomization or data handling.
Sample Ratio Mismatch (SRM): With multiple SRM calculators available online, this must be always checked to ensure that in a A/B test the split is along the expected lines.
Outlier removal: Outliers, if removed, must be removed for the whole data (experiment and control together) and not for each variant. It has been reported that when removed for variants separately, it can inflate the false positive rates by as much as 43% [2].
Degrees of Freedom in Data pre-processing: There are always possibility of removing outliers, adding or reducing data collection in the test and lastly, segmenting data based on variables such as gender etc., to determine the statistically significant hypothesis. Such cases ‘researchers make multiple choices that lead to a multiple-comparison problem and inflate type-I errors’ [2]. It is recommended that, if a new hypothesis emerges, a new test must be conducted by pre-stating the data pre-processing conditions.
Concerns with unequal variant sizes: In theory, a single control can be shared with several treatments. Also, a larger control variant is said to be beneficial in reducing variance [2]. For example: In ramp up, we differ in the size of experiment and control. Example: Control variant might have 98% of the incoming events and 2% of the events might be directed to Experiment variant.
It has been observed that unequal variant sizes can be beset with problems such as ‘Cookie Churn’ - when a cookie is reset then there is high possibility of contamination where the user belonging to experiment variant being exposed to control variant due to the sheer size mismatch between the two variants. Other problems are ‘Shared Resources’ say Caching where experiment variant being smaller is size gives worser performance compared to control variant as the caches implement LRU (Least Recently Used) algorithm.
Lastly, ‘when distributions are skewed, in an unequal assignment, the t-test cannot maintain the nominal Type-I error rate on both tails. When a metric is positively skewed, and the control is larger than the treatment, the t-test will over-estimate the Type-I error on one tail and under-estimate on the other tail because the skewed distribution convergence to normal is different. But when equal sample sizes are used, the convergence is similar and the Δ(observed delta) is represented well by a Normal-distribution or t-distribution’ [2].

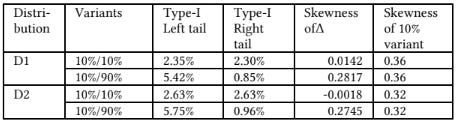
Table 1: Type I errors at left and right tails from 10,000 simulation runs for two skewed distributions when A-A experiment was conducted For experiment ramp-up, where the focus is to reject at the left tail so we can avoid degradation of experiences to users, using a much larger control can lead to higher-than-expected false rejections.
Note that according to authors[2], two major sources of skewness in experimental data are heavy-tailed measurements such as revenue and counts which are often zero-inflated at the same time and binary/conversion metric with have a very small positive rate.
Choosing the best possible OEC or Performance metric: Ron Kohavi et al [3] suggest usage of metrics that have lower variability. Example, conversion rate has lower variability than amount of units purchased which in turn has lower variability than revenue generated.
Speed and its relation to performance metric: Sometimes the system performance of the treatment, say load time of the particular treatment widget, may led to poorer performance of the treatment. Example: at Google, an experiment increased the time to display search results by 500 msecs and led to reduction in revenues by as much as 20% [3].
Filtering users that add to noise: Some rule of thumbs for making sure the A/B test is not inundated with users who add noise to the test:
Remove users who have not been directly exposed to the test. This reduces the variability of the performance metric. Example: If tracking conversion ratio on the checkout page, only user who reach the checkout page should be tracked. Tracking all users opening the website or anywhere before in the funnel adds noise to the performance metric.
Filter robots: Robots can significantly skew the performance metric and render assumptions invalid. Moreover it is necessary to remove robots that interact with user id. Also, robots that reject cookies, should not be included in the test. Additionally, robots that accept cookies and don’t delete them have been found to show 7000 clicks on a page per hour, significantly acting as outliers in the test and skewing the performance metric [3].
References
This article has used the following research papers as references :
Statistical Challenges in Online Controlled Experiments: A Review of A/B Testing Methodology
A/B Testing Intuition Busters: Common Misunderstandings in Online Controlled Experiments
Controlled experiments on the web: survey and practical guide
Thanks for a nice summary.
To learn more, see my book at https://experimentguide.com and interactive online course on A/B Testing: https://bit.ly/ABClassRKLI.