


How to understand NLP models using LIME?
Explains the predictions of any classifier in an interpretable and faithful manner.

Data Science is a fast evolving field where most of the ML models are still treated as black boxes. Understanding the reason behind the predictions is one of the most important task one needs to perform in order to assess the trust if one plans to take action based on the predictions provided by the machine learning models.
This article deals with a novel explanation technique known as LIME that explains the predictions of any classifier in an interpretable and faithful manner.
What is LIME?
LIME, or Local Interpretable Model-Agnostic Explanations, is an algorithm which explains the prediction of classifier or regressor by approximating it locally with an interpretable model. It modifies a single data sample by tweaking the feature values and observes the resulting impact on the output. It performs the role of an “explainer” to explain predictions from each data sample. The output of LIME is a set of explanations representing the contribution of each feature to a prediction for a single sample, which is a form of local interpretability.
Why LIME?
LIME explains a prediction so that even the non-experts could compare and improve on an untrustworthy model through feature engineering. An ideal model explainer should contain the following desirable properties:
Interpretable
LIME provides a qualitative understanding between the input variables and the response which makes it easy to understand.Local Fidelity
It might not be possible for an explanation to be completely faithful unless it is the complete description of the model itself. Having said that it should be at least locally faithful i.e. it must replicate the model’s behavior in the vicinity of the instance being predicted and here too LIME doesn’t disappoints us.Model Agnostic
LIME can explain any model without making any prior assumptions about the model.Global perspective
The LIME explains a representative set to the user so that the user can have a global intuition of the model.
Let’s have a quick look on a practical example of using LIME on a classification problem.
Importing the libraries
import numpy as np
import pandas as pd
import sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import make_pipeline
from lime.lime_text import LimeTextExplainer
from vevestaX import vevesta as vLoading the Dataset
For Dataset Click here.
df=pd.read_csv('IMDB Dataset.csv')
df.head()
Data Preprocessing and Train-Test-Split
Here, we will be using the technique of Tf-Idf Vectorization in order to convert the words to numeric vectors so that it can be easy for the machine to understand it.
x=df.review
y=df.sentiment
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=7, stratify=y)vectorizer = TfidfVectorizer(max_features=5000,stop_words='english')
x_train_vec=vectorizer.fit_transform(x_train.values).toarray()
x_test_vec=vectorizer.transform(x_test.values).toarray()Model Training
model = RandomForestClassifier()
model.fit(x_train_vec, y_train)Introducing LIME
The initial step in this process is to make a pipeline which converts text data to vectorize format and then passes it to the model.
The pipeline is required because explain instance from the LimeTextExplainer takes only string as an input therefore in order to make it compatible for the model to understand we make use of pipelines.
pipeline = make_pipeline(vectorizer, model)Moving ahead in order to get the explanation of the records we would be using a record from x_test dataset having an index of 655. We can use any other index and can get the explanation for the same.
Note that LIME takes individual record as an input and then provide its corresponding explanation as output.
Original value corresponding to the index 655 of x_test is ‘negative’. Thus what we can expect from LIME is to provide the explanation for the negative probability of index 655.
ind=655
text=x_test[ind]y_test
#negativeThis is how the explanations look for the index 655 of test data.
class_names = [‘negative’,’positve’]
explainer = LimeTextExplainer(class_names=class_names)exp = explainer.explain_instance(text,pipeline.predict_proba, num_features=10)
exp.show_in_notebook(text=True)
There are three parts to the explanation :
The left most section displays prediction probabilities, here in our case probability of being a negative comment comes out to be 0.68 whereas 0.32 for the comment to be a positive one.
The middle section returns the most impactful words. For the binary classification task, it would be in 2 colors orange/blue. Attributes in orange support positive class and those in blue support negative. Float point numbers on the horizontal bars represent the relative importance of these words.
The right most section returns the text with the most impactful words highlighted.
Dumping the Experiment
V.dump(techniqueUsed='LIME',filename="nlp_LIME.xlsx",message="LIME was used",version=1)Subscribe to receive a copy of our newsletter directly delivered to your inbox.
Brief Intro about VevestaX
VevestaX is an open source Python package which includes a variety of features that makes the work of a Data Scientist pretty much easier especially when it comes to analyses and getting the insights from the data.
The package can be used to extract the features from the datasets and can track all the variables used in code.
The best part of this package is about its output. The output file of the VevestaX provides us with numerous EDA tools like histograms, performance plots, correlation matrix and much more without writing the actual code for each of them separately.
How to Use VevestaX?
Install the package using:
pip install vevestaXImport the library in your kernel as:
from vevestaX import vevesta as v
V=v.Experiment()To track the feature used:
V.ds = dataframeTo track features engineered
V.fe = dataframeFinally in order to dump the features and variables used into an excel file and to see the insights what the data carries use:
V.dump(techniqueUsed='LIME',filename="LIME_nlp.xlsx",message="LIME was used",version=1)Following are the insights we received after dumping the experiment:
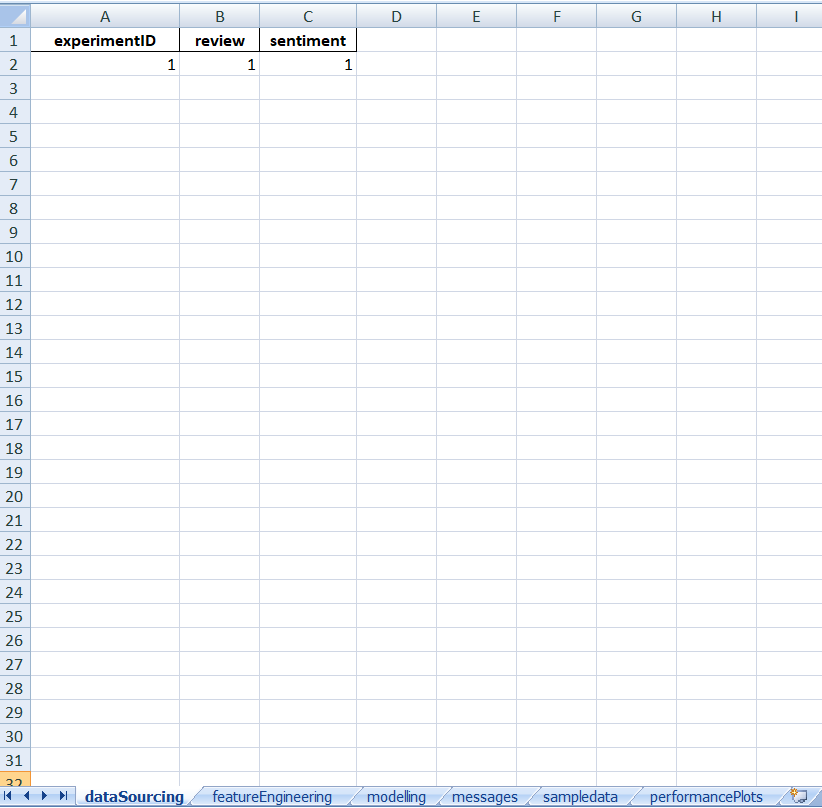
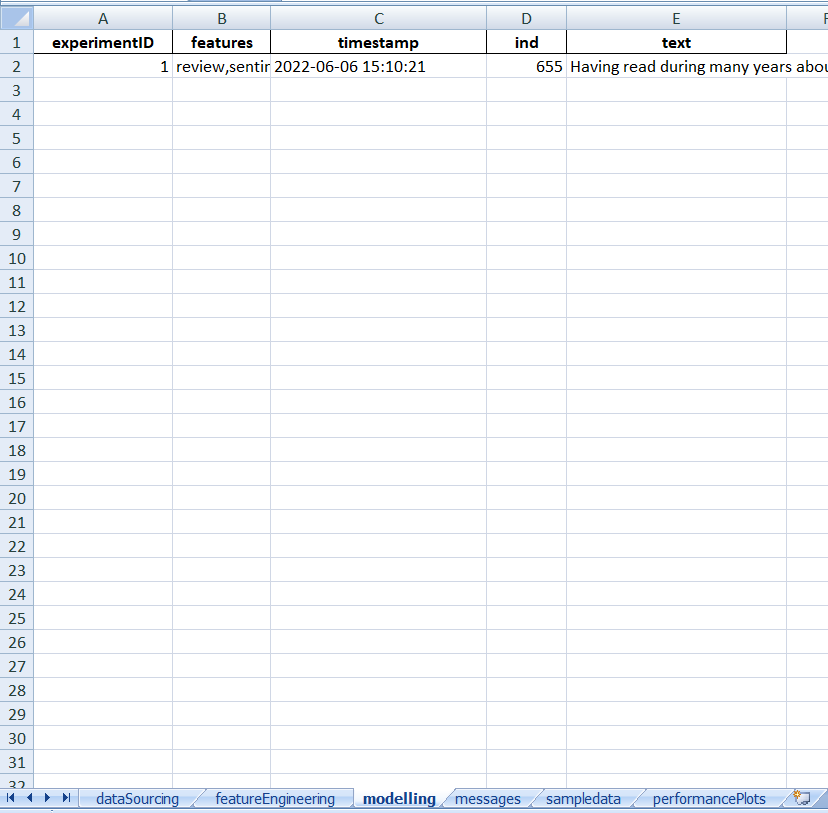
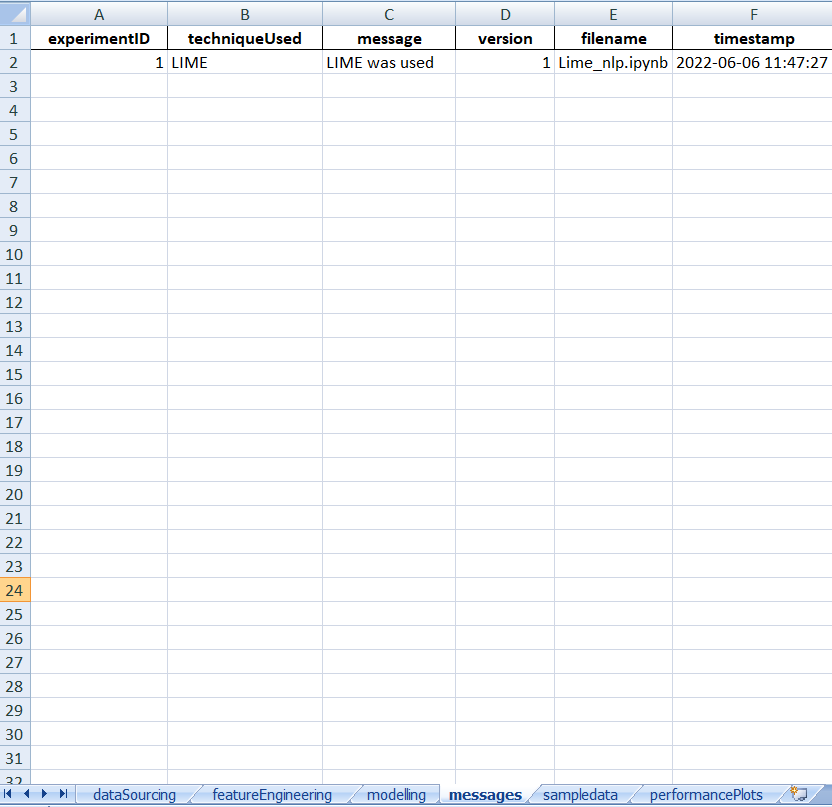
Here ends our look at using the LIME Package in Machine Learning Models.
The above article is sponsored by Vevesta.
Vevesta: Your Machine Learning Team’s Collective Wiki: Identify and use relevant machine learning projects, features and techniques.
100 early birds to login to Vevesta get free subscription for the tool for 3 months.
Subscribe to receive a copy of our newsletter directly delivered to your inbox.
References