
How to provide fairness and minimize the bias when implementing AI and Machine Learning algorithms
AI Fairness (Bias Handling) of Machine Learning Algorithms

Although there is high demand in corporate world to leverage the power of artificial intelligence and machine learning, it is important to provide fairness and minimize the bias when implementing AI and ML algorithms.
There are cases where the companies have to face severe penalties due to their unfair implementation of AI and ML practices. American Express is one such example that had to pay a settlement of $96 million for credit discrimination of more than 220,000 of its customers. A similar case has happened with American Honda Finance Corp. and Ally Bank/Ally Financial and together they need to pay a settlement of $104 million to African-American, Hispanic, Asian and Pacific Island borrowers for its discriminatory practices.
Like this there are many examples where companies have to face the penalties due to partial or biased implementation of Machine Learning Models.
Protected Attributes
According to the discrimination law, Protected Attributes are the personal characteristics of a person that cannot be used as a reason to discriminate against him/her or treat him/her unfairly. Here is the list of Protected attributes:
Age
Color
Marital status (single or married)
National origin
Race
Recipient of public assistance
Religion
Sex
These attributes are the features that should not be used as the basis for decisions in machine learning models. Even when these classes of attributes aren’t being used in machine learning models, discrimination may still exist due to some correlation. That discrimination can be unintentional (disparate impact) or intentional (disparate treatment).
Disparate Treatment vs Disparate Impact
Disparate Treatment is when we are disproportionately favoring a particular protected class by intentionally including variables tied to protected attributes whereas Disparate Impact is when we are disproportionately favoring a particular group unintentionally.
How to Identify Disparate Impact?
Disparate Impact is a metric to evaluate fairness. It compares the proportion of individuals that receive a positive output for two groups: an unprivileged or the minority group and a privileged or a majority group.
The calculation is the ratio of the unprivileged group that received the positive outcome to the proportion of the privileged group that received the positive outcome.
P(Y=1|D=unprivileged)/P(Y=1|D=privileged)
To identify the existence of disparate impact the Pareto Principle or the 80% Rule is used.
For example, if 650 is considered a prime score, and 80% of an ethnic majority group score above 650 and only 20% of ethnic minority score above 650, then there is discrimination at play according to the 80% rule. The 80% rule is one of the techniques regulators use for testing fairness.
In this article we will be choosing a biased dataset to train a model and then will be using AI Fairness 360, an open-source toolkit by IBM Research in order to mitigate the bias.
The Dataset
The selected dataset contains information about the loan applicants, as well as whether the loan was approved or denied. The dataset was purposely chosen as it clearly contains legally protected groups/classes with it.
In this dataset, there are three variables that are directly associated with protected classes that one should check for bias against: Gender, Married, and Dependents. However in this article we will be restraining ourselves to Gender only.
Importing the libraries
import numpy as np
import pandas as pd
import aif360
from vevestaX import vevesta as v
#Create an Experiment Object
V=v.Experiment()
from aif360.algorithms.preprocessing import DisparateImpactRemover
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
pd.options.mode.chained_assignment = None # default='warn', silencing Setting With Copy warningLoading the Dataset and Basic Data Preprocessing
df=pd.read_csv('credits.csv')
df.head()
Encoding Categorical Variables
df.Gender=df.Gender.replace('Male',1)
df.Gender=df.Gender.replace('Female',0)
df.Loan_Status=df.Loan_Status.replace('Y',1)
df.Loan_Status=df.Loan_Status.replace('N',0)# Replace the categorical values with the numeric equivalents that we have above
categoricalFeatures = ['Property_Area', 'Married', 'Dependents', 'Education', 'Self_Employed']
# Iterate through the list of categorical features and one hot encode them.
for feature in categoricalFeatures:
onehot = pd.get_dummies(df[feature], prefix=feature)
df = df.drop(feature, axis=1)
df = df.join(onehot)
df
Feature Scaling and Train-Test-Split
from sklearn.model_selection import train_test_split
encoded_df = df.copy()
x = df.drop(['Loan_Status'], axis = 1)
y=df.Loan_Status
y=y.astype(int)from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data_std = scaler.fit_transform(x)x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.2, random_state = 0)
Calculating actual disparate impact on testing values from original dataset
actual_test = x_test.copy()
actual_test['Loan_Status_Actual'] = y_test# Priviliged group: Males (1)
# Unpriviliged group: Females (0)male_df = actual_test[actual_test['Gender'] == 1]
num_of_priviliged = male_df.shape[0]
female_df = actual_test[actual_test['Gender'] == 0]
num_of_unpriviliged = female_df.shape[0]unpriviliged_outcomes = female_df[female_df['Loan_Status_Actual'] == 1].shape[0]
unpriviliged_ratio = unpriviliged_outcomes/num_of_unpriviliged
unpriviliged_ratiopriviliged_outcomes = male_df[male_df['Loan_Status_Actual'] == 1].shape[0]
priviliged_ratio = priviliged_outcomes/num_of_priviliged
priviliged_ratio# Calculating disparate impact
disparate_impact = unpriviliged_ratio / priviliged_ratio
print("Disparate Impact, Sex vs. Predicted Loan Status: " + str(disparate_impact))
We can see here that our Disparate Impact on testing values from original dataset comes out to be around 0.83.
This indicates that the actual test split favors the privileged group (males), as a disparate ratio of 1 indicates complete equality.
More the disparate ratio is closer to 1,less the bias our features are.
Now we are using Logistic Regression in order to train the dataset and then will perform Disparate Impact on on the predicted values of dataset.
Training the model
from sklearn.linear_model import LogisticRegression
# Liblinear is a solver that is very fast for small datasets, like ours
model = LogisticRegression(solver='liblinear', class_weight='balanced')
model.fit(x_train, y_train)Evaluating Model Performance

Calculating disparate impact on predicted values by model trained on original dataset.

From here what we can notice is that our Impact Ratio has declined when compared with the actual test values that means the bias got amplified while training the model.
Now from here how we will be proceeding further is like that we will be applying Disparate Impact Remover provided by AIF 360 toolkit on the original dataset which in turn will edit the feature values to increase group fairness.
The algorithm requires the user to specify a repair_level, this indicates how much the user wish for the distributions of the groups to overlap. Let’s explore the impact of two different repair levels, 1.0 and 0.8.
Repair value = 1.0

The diagram shows the repaired values for Feature for the unprivileged group Blue and privileged group Orange after using DisparateImpactRemover with a repair value of 1.0.
Here we are no longer able to select a point and infer which group it belongs to. This would ensure no group bias is discovered by a machine learning model.
Repair value = 0.8

The diagram shows the repaired values for Feature for the unprivileged group Blue and privileged group Orange after using DisparateImpactRemover with a repair value of 0.8.
The distributions do not entirely overlap but we would still struggle to distinguish between membership, making it more difficult for a model to do so.
Applying the Pre-Processing
Now in order to apply disparate impact removal algorithm the AIF 360 requires user to convert the Pandas Data Frame to a datatype called as BinaryLabelDataset.
Thus, we will be converting Pandas Data Frame to Binary Label Dataset and then we will be creating a DisparateImpactRemover object, which is used to run a repairer on the non-protected features of the dataset.
import aif360
from aif360.algorithms.preprocessing import DisparateImpactRemover# binaryLabelDataset = aif360.datasets.BinaryLabelDataset(
# df=yourDataFrameHere,
# label_names=['yourOutcomeLabelHere'],
# protected_attribute_names=['yourProtectedClassHere'])
# Must be a binaryLabelDatasetbinaryLabelDataset = aif360.datasets.BinaryLabelDataset(
favorable_label=1,
unfavorable_label=0,
df=encoded_df,
label_names=['Loan_Status'],
protected_attribute_names=['Gender'])di = DisparateImpactRemover(repair_level = 1.0)
dataset_transf_train = di.fit_transform(binaryLabelDataset)
transformed = dataset_transf_train.convert_to_dataframe()[0]
transformed
Training the Model (after pre-processing)
The preprocessed data set was again subjected to the similar steps of model training like train_test_split, model fitting, performance evaluation and Disparate Impact Calculation.

Performance Evaluation

Calculating Disparate Impact

We can notice here that the disparate impact ratio has been found to be around 0.711 which is relatively more when compared with the disparate impact ratio produced by the model trained on the original, unmodified data.
Dumping the Experiment
V.dump(techniqueUsed='AIF360',filename="AIF.xlsx",message="AIF 360 was used",version=1)
Conclusion
The aim of the article was to explore how bias gets easily amplified in ML models as well to look for the potential approaches to mitigate bias. Before the model training , we had already observed bias in the original dataset’s testing values (with a disparate income ratio of .83). When we had trained the model and evaluated its predictive values for bias, the bias got significantly worsen than before (with a disparate income ratio of .66). We then applied a pre-processing technique known as disparate impact removal and trained the model using the transformed data. This resulted in predictive values with less bias (with a disparate income ratio of .71). This is still far from ideal but better when compared with the previous one.
Subscribe to our weekly newsletter to stay updated on latest machine learning/MLOps articles.
Brief Intro about VevestaX
VevestaX is an open source Python package which includes a variety of features that makes the work of a Data Scientist pretty much easier especially when it comes to analyses and getting the insights from the data.
The package can be used to extract the features from the datasets and can track all the variables used in code.
The best part of this package is about its output. The output file of the VevestaX provides us with numerous EDA tools like histograms, performance plots, correlation matrix and much more without writing the actual code for each of them separately.
How to Use VevestaX?
Install the package using:
pip install vevestaXImport the library in your kernel as:
from vevestaX import vevesta as vV=v.Experiment()To track the feature used:
V.ds = dfwhere df is the pandas data frame containing the features.
To track features engineered
V.fe = dfFinally in order to dump the features and variables used into an excel file and to see the insights what the data carries use:
V.dump(techniqueUsed='AIF360',filename="AIF.xlsx",message="AIF 360 was used",version=1)
V.commit(techniqueUsed = "AIF360", message="AIF 360 was used", version=1, projectId=128, attachmentFlag=True)Following are the insights we received after dumping the experiment:

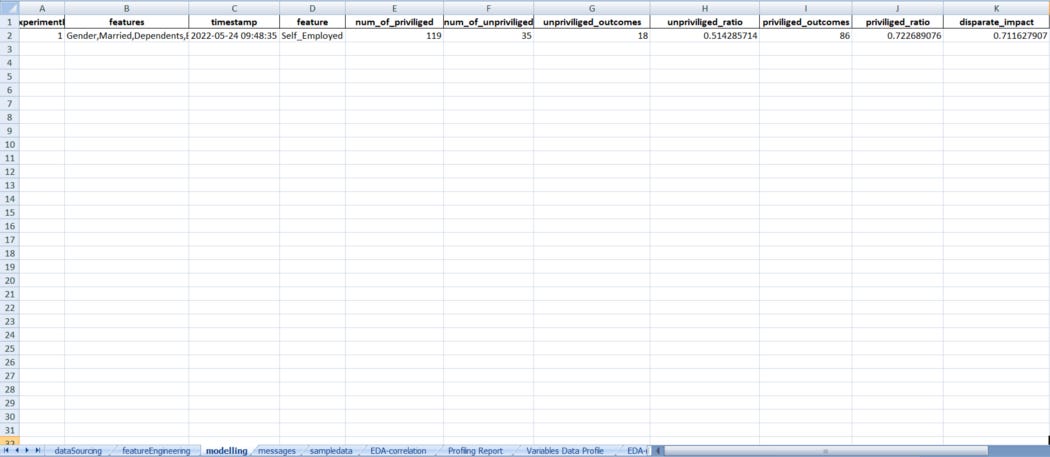






This completes our look at Bias Handling in Machine Learning Models.
Credits
The above article is sponsored by Vevesta.
Vevesta: Your Machine Learning Team’s Collective Wiki: Identify and use relevant machine learning projects, features and techniques
For more such stories, follow us on twitter at @vevesta1
100 early birds who login to Vevesta get free subscription for 3 months.
References