
How activation function Swish outperforms ReLU ?
Deep dive into relativity new and unexplored activation function, Swish

The choice of activation functions in Deep Neural Networks creates a major impact on the training dynamics and task performance.
Activation Function helps the neural network to use important information while suppressing irrelevant data points.
The role of the Activation Function is to derive output from a set of input values fed to a layer.
Currently, the most successful and widely-used activation function is Rectified Linear Unit also known as ReLU, the mathematical representation of which is f(X)=max(0,X). ReLU has been widely accepted as the default activation function because of its versatility in different task domains and types of networks, as well as its low computation complexity.
For a long period of time various alternatives to ReLU were tried but none of them could match up with its accuracy and ease of usage. Finally in 2017, Google’s brain team came with a new activation function Swish which in most of the cases overperformed ReLU and thus served as an alternative to it.
Swish is a non-monotonic function with a smooth curve which consistently matches or outperforms the accuracy of ReLU. It is Bounded below but Unbounded above i.e. Y approach to constant value as X approaches negative infinity but Y approach to infinity as X approaches infinity.
Mathematically Swish can be defined as Y=X* sigmoid(βX) which is just a slight modification of activation function SiLU which is Y=X* sigmoid(X).
Advantages of Swish over ReLU Activation Function:
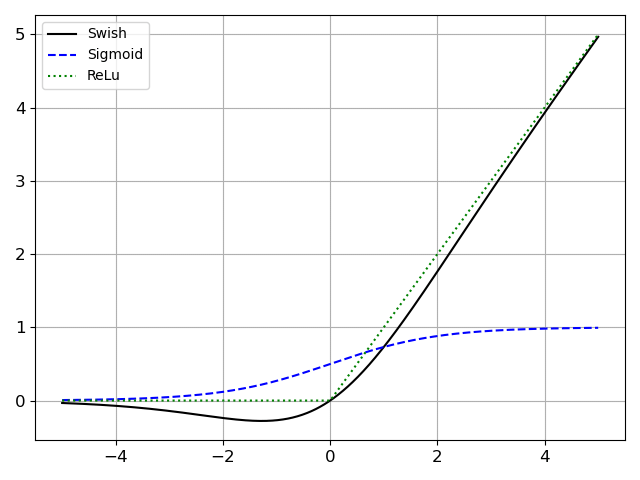
Swish is a smooth continuous function, unlike ReLU which is a piecewise linear function.
Swish allows a small number of negative weights to be propagated through, while ReLU thresholds all negative weights to zero. This is an extremely important property and is crucial in the success of non-monotonic smooth activation functions, like that of Swish, when used in increasingly deep neural networks.
In Swish, the trainable parameter allows to better tune the activation function to maximize information propagation and push for smoother gradients, which makes the landscape easier to optimize, thus generalizing better and faster.
Performance
The authors of the Swish paper compare Swish to the following other activation functions:
Leaky ReLU, where f(x) = x if x ≥ 0, and ax if x < 0, where a = 0.01. This allows for a small amount of information to flow when x < 0, and is considered to be an improvement over ReLU.
Parametric ReLU is the same as Leaky ReLU, but a is a learnable parameter, initialized to 0.25.
Softplus, defined by f(x) = log(1 + exp(x)), is a smooth function with properties like Swish, but is strictly positive and monotonic.
Exponential Linear Unit (ELU), defined by f(x) = x if x ≥ 0 and a(exp(x) — 1) if x < 0 where a = 1.
Scaled Exponential Linear Unit (SeLU), identical to ELU but with the output multiplied by a value s.
The below table demonstrates how many times Swish performed better, equal, or worse than the outlined baseline activation functions at 9 experiments.

The above article is sponsored by Vevesta.
Vevesta: Your Machine Learning Team’s Collective Wiki: Identify and use relevant machine learning projects, features and techniques
100 early birds who login to Vevesta will get free subscription for 3 months.
Subscribe to our weekly newsletter to stay updated on latest machine learning/MLOps articles.
References