
OptFormer: Google's Improved Hyperparameter Optimization Technique
Optimizers with Transformers


Hyperparameters are defined as the parameters that are explicitly defined by the user to control the learning process before applying a machine-learning algorithm to a dataset.
What makes hyperparameters stand out, when compared to parameters?

Parameters are configuration variables that are internal to the model, and a model learns them on its own that means they are not set manually. Whereas hyperparameters are set manually by the machine learning engineer. The best value can be determined either by the rule of thumb or by trial and error.
The process of selecting the best hyperparameters to use is known as hyperparameter tuning, and the tuning process is also known as hyperparameter optimization. As the name suggests, optimization parameters are used for optimizing the model.
Tuning hyperparameters helps machine learning models generalize well. Generalization refers to the ability of the model to perform well on training data as well as on new data.
Google uses Google Vizier as the default platform for hyperparameter optimization. As it keeps track of patterns in its database contain very valuable prior information on realistic hyperparameter tuning objectives and are thus highly attractive for developing better algorithms. There is one major drawback: the meta-learning procedures depend heavily on numerical constraints such as the number of hyperparameters and their value ranges, and thus require all tasks to use the exact same total hyperparameter search space (i.e., tuning specifications). Such a drawback becomes more exacerbated for larger datasets, which often contain significant amounts of such meaningful information.
To solve this problem, Google launched OptFormer - one of the first Transformer-based frameworks for hyperparameter tuning, learned from large-scale optimization data using flexible text-based representations. This depicts the following abilities:
A single Transformer network is capable of imitating highly complex behaviors from multiple algorithms over long horizons.
The network is further capable of predicting objective values very accurately, in many cases surpassing Gaussian Processes, which are commonly used in algorithms such as Bayesian Optimization.
The data in databases usually consisting of optimization trajectories termed as studies. The previous methods used only numerical data. But OptFormer represents all study data including textual information from initial metadata as a sequence of tokens.

The animation above includes “CIFAR10”, “learning rate”, “optimizer type”, and “Accuracy”, which informs the OptFormer of an image classification task. The OptFormer then generates new hyperparameters to try on the task, predicts the task accuracy, and finally receives the true accuracy, which will be used to generate the next round’s hyperparameters.
The OptFormer can perform hyperparameter optimization encoder-decoder style, using token-based representations. It initially observes text-based metadata (in the gray box) containing information such as the title, search space parameter names, and metrics to optimize, and repeatedly outputs parameter and objective value predictions.
1. Imitating Policies
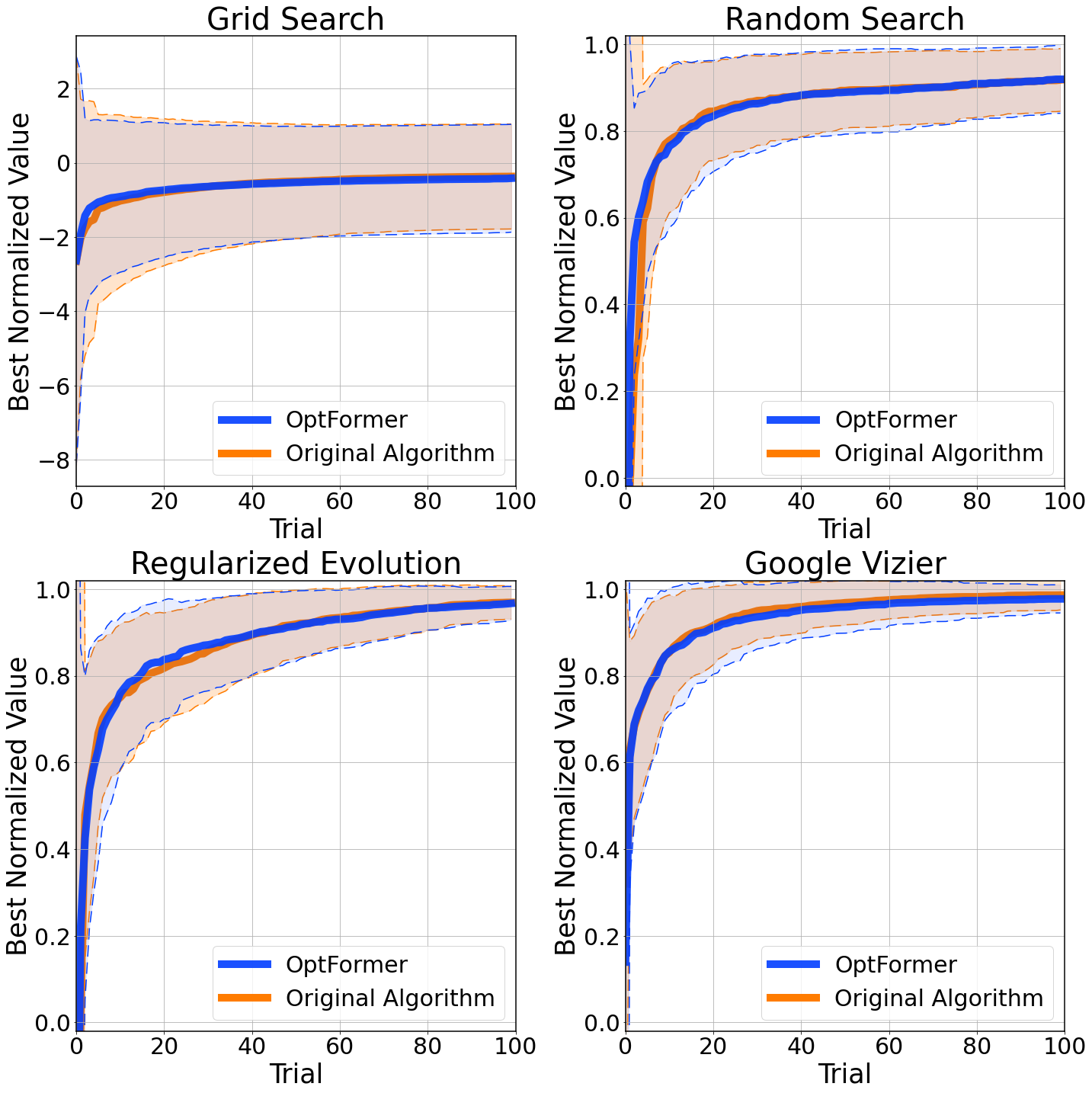
OptFormer is used to imitate algorithm’s behavior simultaneously as it is trained over optimization trajectories. Over an unseen test function, the OptFormer produces nearly identical optimization curves as the original algorithm. Mean and standard deviation error bars are shown.
2. Predicting Objective Values
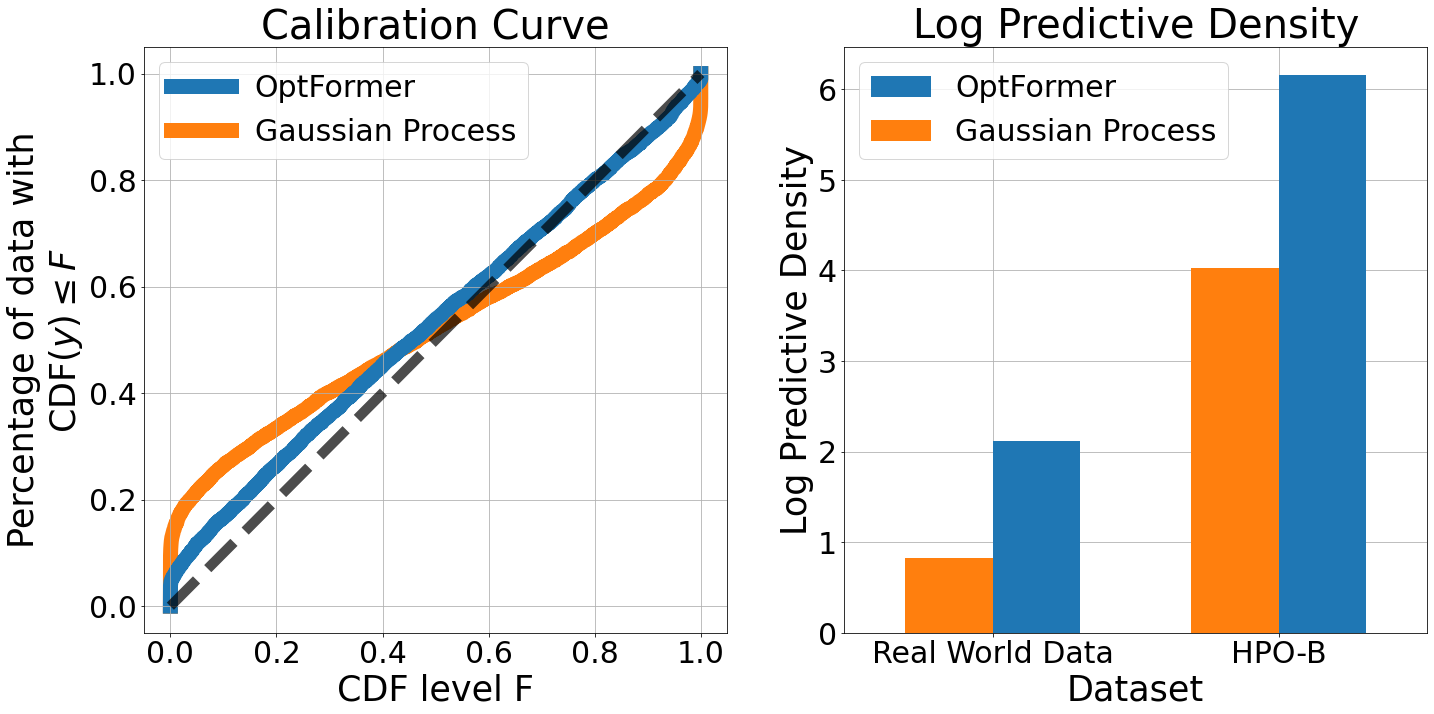
In the figure below, as compared to Gaussian Process, OptFormer makes significantly more accurate predictions of objective values being optimized (e.g., accuracy) and provide uncertainty estimates.
(Left) Qualitatively: OptFormer’s calibration curve closely follows the ideal diagonal line in Rosenblatt goodness-of-fit test. (Closer diagonal fit is better)
(Right) Quantitatively: OptFormer’s standard aggregate metrics such as log predictive density is high. (Higher is better)
Combining Both: Model-based Optimization
Now, we put in use the OptFormer’s function prediction capability to better guide our imitated policy. Imitated policy suggestions are ranked using Thompson Sampling and only the best according to the function predictor is selected.
As compared to Google Vizier’s Bayesian Optimization, OptFormer outperforms the industry-grade algorithm by producing an augmented policy when optimizing classic synthetic benchmark objectives and tuning the learning rate hyperparameters of a standard CIFAR-10 training pipeline.

Left: Best-so-far optimization curve over a classic Rosenbrock function.
Right: Best-so-far optimization curve over hyperparameters for training a ResNet-50 on CIFAR-10 via init2winit. Both cases use 10 seeds per curve, and error bars at 25th and 75th percentiles.
Vevesta: Your Machine Learning Team’s Feature and Technique Repository - Accelerate your Machine learning project by using features, techniques and projects used by your peers
100 early birds who login into Vevesta will get free subscription for lifetime.
References
This article was originally published at https://www.vevesta.com/blog/36-OptFormer