
Everything you need to know about Distributed training and its often untold nuances
Understanding Data Parallelism vs Model Parallelism, Their Powers and Their Kryptonite (weakness)

The idea of dividing portions of work to obtain exceptional results, in a short amount of time and thereby reducing the overall strain is exactly the gist of our topic called “Distributed Training”, which has led to some very interesting research in the field of machine learning pushing our technology another leap ahead.
Introduction To Distributed Training
The number of parameters in modern deep learning models is growing exponentially, and the size of the data set is also increasing at a similar rate. Therefore dividing one huge task into a number of subtasks to run them parallelly makes the whole process much more time efficient and enables us to complete complex tasks with ginormous datasets. This is what we call as distributed training.
To put it simply, by using multi-node training, we train massive deep learning models which would require ages to train otherwise. There are two main branches under distributed training, called:-
Data Parallelism
Model Parallelism
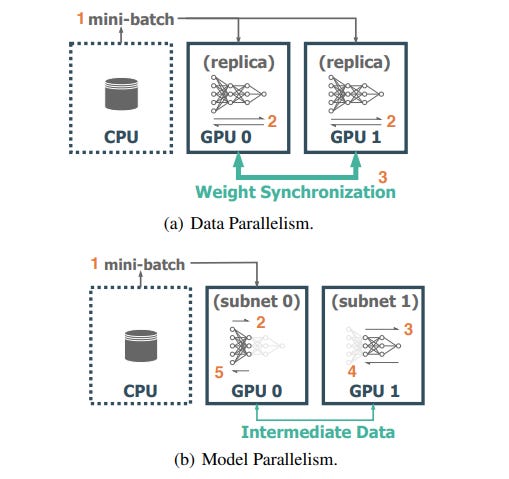
Data Parallelism
In data parallelism, the giant dataset is split up into parts. Each part has its own GPU. These GPUs are then connected to parallel computational machines. The gradients collected from different batches of data are then collected and the values are merged to get the final result.
For every GPU or node, the generic parameters are kept constant and the network ideally is a feed-forward network, where a small batch of data is sent to every node, and the gradient is computed normally and sent back to the main node. Data parallelism uses inter-GPU communication for talking with other nodes and GPUs to get gradients for proper weight synchronization.
There are two approaches to data parallelism which are:-
Synchronous Training
As a part of sync training, the model sends different parts of the data into each node. Each model is totally identical to the original model, the only difference between them being the different batch of data that is being trained. The network here works in forward propagation parallelly which gives distinct results and gradients.
Synchronous training uses an all-reduce algorithm that collects all the trainable parameters from various nodes and accelerators. While synchronous training can be advantageous in many ways, it is harder to modify and scale to the growing need for computation resulting in unused nodes with zero work.
Asynchronous Training
The specialty of asynchronous training is its property to scale with the amount of data available and speed up the rate at which the entire dataset contributes to the optimization.
Unlike synchronous training, in asynchronous training, the nodes work independently in such a way that a worker node need not wait for any other worker node in the cluster. One way to achieve this is by using a parameter server, as it holds the parameters of the model which are responsible for updating the global state of our model and requires less communication between nodes, and also benefits from a high amount of computations per weight.
Model Parallelism

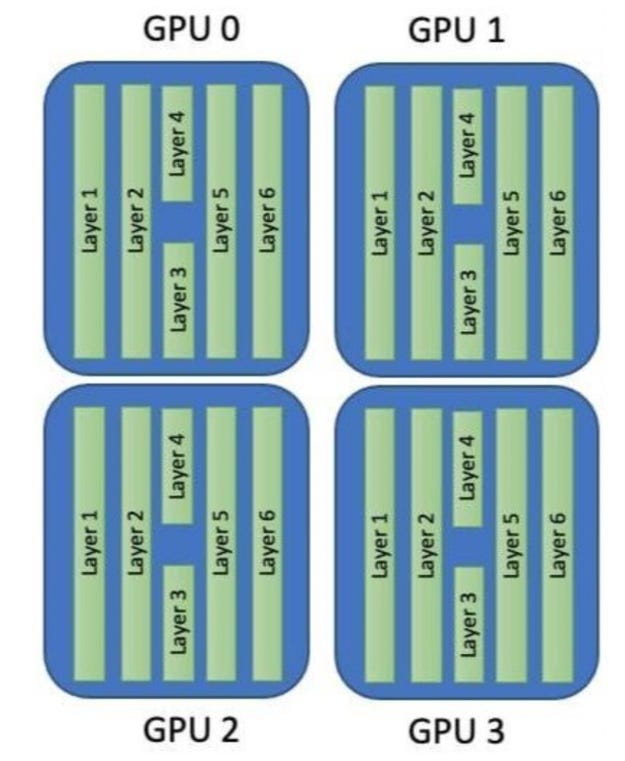
In model parallelism, instead of the data being split up into parts, the model is divided into separate parts and now these individual parts will have their own GPU. That is, each GPU takes as input the data flowing into a particular layer, processes data across several subsequent layers in the neural network, and then sends the data to the next GPU.
The batch of GPUs is then calculated sequentially in this manner, starting with the first one onto the final GPU, making this into a forward propagation. Backward propagation on the other hand begins with the final and ends at the first GPU. Model parallelism also needs an acute amount of inter-GPU communication to transfer all intermediate data between sub-models.
Model parallelism has some obvious benefits. It can be used to train a model such that it does not fit into just a single GPU. But when computation is moving sequentially, for example, when the first GPU is in computation, the others simply lie idle. This can be resolved by shifting to an asynchronous style of GPU functioning.
A study titled ‘Efficient and Robust Parallel DNN Training through Model Parallelism as Multi-GPU Platform’ tested model parallelism versus data parallelism. We shall take a deeper look into the results of the given theory.
Drawbacks of Data Parallelism and How Model Parallelism Overcomes it
So far, we have seen how to distribute the data and train the model in multiple devices with different chunks of data and this approach works most of the time and is easy to implement as well. Following are the advantages of using Model Parallelism:
In some rare situations, the size of the model may be too large for any single worker, which is why we need model parallelism wherein we split the model itself to make computing faster.
As said earlier, it is harder to modify and scale to the growing need for computation resulting in unused nodes or workers with zero work. But in model parallelization, since all models are split up and work coherently there is much less loss in computation.
Both data parallelism and model parallelism need inter-GPU communications. The study shows that practically data parallelism requires more inter-GPU communication generally than model parallelism.
While some of the implemented data-parallelization required almost no communication between GPUs when model parallelism is applied since these models have fewer intermediate data between layers.
In the figure below, we see how different parallelizations use GPU cross-talking and the likely hood of time wasted while communicating.
This dependency on inter-GPU communications of data parallelism leads up to a considerable slowdown. On average 26.7% of training time is spent on inter-GPU data transfer when data parallelism is applied.
In the figure below has the amount of time Data Parallelism uses for Inter-GPU communication vs the time it takes to process and compute the gradients.


Advantages of Data Parallelism Over Model Parallelism
Studies showed that models using data parallelism increase in their accuracy as training proceeds, but the accuracy starts fluctuating with model parallelism.
For model parallelism, if training proceeds in the pipelined manner, it induces the staleness issue. This staleness issue leads to unstable learning and worse model accuracy.
In the figure below, the depicted graph we’re able to see how staleness causes a loss in training accuracy starting from the 2700 iteration leading to the drop ahead to the 5000s.
Data parallelism partitions training data across a whole array of GPUs, therefore, the workload across the GPUs could be easily maintained.
While in, model parallelism, achieving this load balance is more grueling a task. Since the complexity of different Deep Neural Network(DNN) layers varies, it would require loads of time and hard work to partition model layers to GPUs in a balanced way.

Conclusion
Distributed training is used to train huge deep learning models which would require an extremely large amount of time to train generically.
Both, data and model parallelism have their own advantages which could be used following their availability and necessity.
The concept of distributed training has piqued the interest of scientists all around the world and the algorithms and methodologies are leading to more discoveries.
Distributed training implements GPUs for training, hence it is the groundwork for learning how GPUs are used to train models and push data.
Subscribe to receive a copy of our free newsletter directly delivered to your inbox.
Vevesta: Your Machine Learning Team’s Feature and Technique Dictionary - Accelerate your Machine learning project by using features, techniques and projects used by your peers
100 early birds who login into Vevesta will get free subscription for 3 months
References
This article was originally published at https://www.vevesta.com/blog/32-Distributed-Training