
Deep Dive into how Predicting Future Weights of Neural Network is used to mitigate Data Staleness while Distributed Training
Introducing SpecTrain as means to predict future weights of neural network to alleviate data staleness and improve speed of training via distributed training


Distributed training of neural networks has seen quite a boom in the technological field today. Well-renowned software development companies have turned their attention towards distributed training, each day coming up with intriguing new research, exceeding the limitations and fine-tuning to make it easy for the masses to learn and develop more from a more economical standpoint.
We are going to ponder, about one such limitation known as the Staleness issue which proves to be unfavorable while implementing Distributed Training using Model Parallelism.
Before we go into detail it is suggested that you have a good hunch about distributed training. Feel free to read through - Everything you need to know about Distributed training and its often untold nuances as it would help with a smoother progression through this article.
Staleness Issue
In model parallelism, when the training proceeds in the pipelined manner, it is seen that the staleness issue is gradually induced which dampens the performance of the neural network. This staleness issue starts very subtly but in due time leads to unstable learning and decreases the model accuracy.

The figure shows the comparison of model accuracy, i.e, the percentage of correct classifications, between model and data parallelism.
We observe that when compared with data parallelism the accuracy of model parallelism fluctuates more prominently. Since model parallelism is considered to be a more fitting choice for parallelizing Deep Neural Networks finding a way to resolve this issue is a huge priority.
Pipelining and The Cause of Staleness
The Pipeline training is basically a rotation of sample data that was split into a mini-batch, which flows through the pipeline normally forward propagating generating gradients as they move along from one GPU to another. After done with forward propagation(forward pass) of a batch these batches are made to propagate backward (backward pass) to fetch the weight updates from the forward pass. So constructively it is a to and fro action as seen in the figure below.
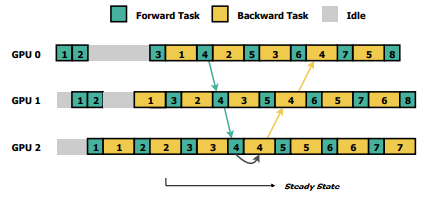
As we can see in the figure, after the completion of one task the GPU asynchronously proceeds to the next task to be time efficient.
The cause of Staleness
Simply put, Staleness occurs when multiple mini-batches are in progress in the pipeline, before earlier mini-batches update weights, the latter mini-batches adopt stale weights to derive gradients.
In pipelined training, a mini-batch is processed by different GPUs are run coherently to finish the forward and backward passes. Since many mini-batches are stacked in the pipeline, weights are continuously updated at every GPU, which causes the mini-batch to adopt inconsistent versions of weights during an iteration.

For example, in Figure the figure above, the 4th mini-batch adopts various versions of weights, ranging from W4 to W6, during its full circle. From the 4th mini-batch’s perspective, W4 and W5 are stale and the only staleness-free version of weights is W6, as W6 is derived after the 3-rd mini-batch updates the weights.
Before the weights could be optimized, another set of the data batch computes considering the same stale weights resulting in a faulty gradient. Such a weight update behavior is called the weight staleness issue and it leads to unstable and inferior convergence.
Staleness Mitigation via SpecTrain
SpectTrain is used to completely rectify the weight staleness and consistency issue. It uses a weight prediction method, which is also easy to apply in the pipeline. In an ideal training procedure, each iteration of a mini-batch should be updated to the same weight version. To maintain weight consistency and avoid staleness, SpecTrain predicts future weights and adopts the predicted weights, rather than the staled version of weights, through a whole iteration of a mini-batch.

As we can see in this illustration, for the same 4th mini-batch instead of adopting different and stale values, by using SpecTrain the GPUs predict the future version of the weight, which is expected to be staleness-free. The staleness-free version originally would be W6. W6 would only be adopted after W4 and W5 but by using SpecTrain the processing of the 4-th mini-batch in its entire round trip is based on W6 rather than W4, giving us the correct gradients, thus improving the accuracy overall.
Weight Prediction
SpecTrain predicts future weights based on the observation that smoothed gradients used in Momentum Stochastic Gradient Decent(SGD), which reflects the trend of weight updates. Momentum SGD is a well-known technique that helps to speed up and improve the stability of SGD by smoothing the weight updates. A smoothed gradient (vt) is the weighted average of recent gradients and is calculated by the following equation:

where γ is the decay factor with 0 < γ ≤ 1 and ‘gt’ is the newly generated gradient. Through averaging with recent gradients by the decay factor, smoothed gradient vt reflects the trend of weight updates. Thus, smoothed gradients can be used to predict future weights.
The Impact SpecTrain Makes
SpecTrain was studied and compared with Data Parallelism along with a regular Model Parallelism method with no staleness reducing agents and PipeDream which is an older alternative that was used to reduce staleness in Data Parallelism.

Each of the experiments is done by training each model for 5000 iterations and training loss, validation loss, and validation accuracy are recorded for every full circle or iteration to show the learning curve. As we see from the results in the study model parallelism with SpecTrain performs exceptionally better than the regular model parallelism.
The Accuracy loss that model parallelism heavily suffered from, with the use of weight prediction is on par with data parallelism, likewise, it also alleviates the instability problem by weight prediction and the learning curve of SpecTrain is similar to data parallelism, indicating that using SpecTrain can achieve near robust training process. Although it doesn’t surpass data parallelism with the features of model parallelism and the results of data parallelism can train Deep neural networks with bulky datasets with ease.
Hence by the research provided to us by Efficient and Robust Parallel DNN training through model parallelism on multi-GPU platform, we can say that SpecTrain resolves the staleness issue. Helping push model parallelism to its limits
Subscribe to receive a copy of our free newsletter directly delivered to your inbox.
Vevesta: Your Machine Learning Team’s Feature and Technique Repository - Accelerate your Machine learning project by using features, techniques and projects used by your peers
100 early birds who login into Vevesta will get free subscription for lifetime.
References
This article was originally published at https://www.vevesta.com/blog/33-Mitigating-Data-Staleness
Interesting