Introducing Etalon: How we choose a LLM with optimal Runtime Performance ?
How to evaluate LLMs and identify best LLM Inference System


I blog about latest machine learning research topics that have an immediate impact on the work us data scientists/machine learning engineers do every day. Share the newsletter with your friends so that we all grow together.
Quick Introduction
User experience and therefore the performance of LLM model in production is crucial for user delight and stickiness on the platform. Currently, LLMs are evaluated using metrics such as TTFT (Time to first Token), TBT (Time between Tokens), TPOT (Time Per Output Token) and Normalized Latency. According to authors[1], the current set of metrics fail to comprehensively analyze the nuances of LLM model during inference, ‘leading to an incomplete assessment of user-facing performance crucial for real-time applications such as chat and translation’. The authors introduce the concept of “Etalon” to better evaluate the performance of LLM models during inference.
Understanding LLM Inference Stages
LLM Inference consists of prefill stage and decode stage. In the prefill stage, the first token is generated by the model. In the decode stage the model generates the 2nd token to the last token by consuming by latest token. The tokens continue to generated till special end-of-sequence token is generated.
Existing Metrics for Measuring LLM’s Performance during Inference Stage
The following metrics are used to evaluate the performance of the LLM model during inference stage:
A. Time To First Token (TTFT)
1. Definition of TTFT
It is ‘the latency between the request arrival and the first output token generated by the system for the request. It includes the scheduling delay (time elapsed from request arrival to start of prompt processing) and the prompt processing time’.
2. Performance Expectation
TTFT needs to be minimized for real-time interactions in order to maintain a responsive and delightful user experience. Also, in contrast, longer TTFT is acceptable in offline or batch processing contexts.
B. Time Between Tokens (TBT)
1. Definition of TBT
It’s the latency of every subsequent token generated in the decode phase.
2. Performance Expectation and Impact
This metric directly influences user experience. According to authors[1], ‘if we assume the average English reading speed is 250 words per minute then a TBT of roughly 6 tokens per second is required. Optimizing TBT enhances the user experience by ensuring rapid and fluid response generation.’
C. Time Per Output Token (TPOT)
1. Definition
Time Per Output Token (TPOT) is ‘the average time to generate an output token in the decode phase. It is calculated as the total decode time of a request normalized by the number of decode tokens generated’ [1]. It is closely related to TBT.
D. Normalized Latency
According to authors[1], ‘it’s defined as the total execution time of a request normalized by the number of decode tokens. It includes the scheduling delay, prompt processing time and time to generate all the decode tokens. Lower normalised latency at a given load (queries-per-second) is desirable.’
E. Capacity
It’s ‘the maximum request load (queries-per-second) a system can sustain while meeting certain latency targets (SLOs). Higher capacity is desirable because it reduces the cost of serving’ [1].
Pitfalls of Existing Metrics
The authors [1] motivation to build another metric for evaluation of runtime inference by LLM systems are the following:
1. Time To First Token (TTFT) is oblivious of prompt length
TTFT is quadratically dependent on the prompt length, which means that larger prompts skew the TTFT in favour of shorter prompts. Also, TTFT also includes the scheduling delay (which depends on the system load, routing policy, batching policy) hence comparing two different LLM systems becomes tricky.
2. Normalized latency hides scheduling delay
According to authors[1], ‘Normalized latency normalizes the request end-to-end time by the total number of decode tokens. However, this ends up hiding specifics about metrics such as scheduling delay.
3. Time Per Output Token and Normalised latency hides jitters in token generation
TPOT and Normalized Latency require normalization of the latency by the number of decode tokens in the request. This normalization masks the jitters that occur due to intermittent stalls during token generation. It is necessary to keep in mind that jitters in generation of tokens impair the user experience.
4. TBT CDFs do not reveal the magnitude and temporal characteristics of stalls
In a autoregressive nature of LLM model, token i is generated using token i-1. Therefore a delay in one token generation delays all subsequent tokens. This scenario impairs the user experience and TBT CDF doesn’t capture this case where delay occurs at the start of token generation.
Etalon and fluidity-index
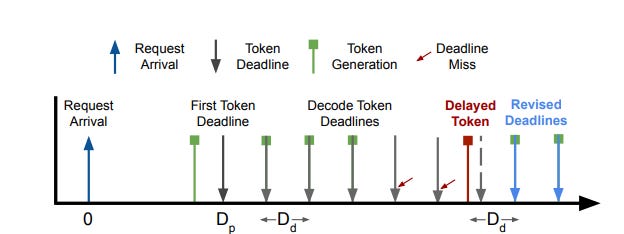
The author’s [1] propose Etalon which is an evaluation framework for LLM inference using ‘fluidity-index metric’ that tracks the missed deadlines per request. Alternatively, they define Fluidity-index as ‘a deadline based TBT acceptance rate metric’.
Deep Dive into Fluidity-index
Following are the definitions:
Let the desired TTFT for a given LLM system be
Dp. We already know that TTFT, i.e.Dp,will be a function of the number of prompt/prefill tokens.Let the desired TBT for a given LLM system be
Dd.The deadline for the generation of the
ithtoken defined as follows :
Di = Dp + i × DdAuthors[1] have emphasized that as long as all tokens are generated within their deadline, Di , the user will not perceive any delay or generation stall, even if some individual tokens see a delay of more than Dd (i.e. TBT) between consecutive token generation.
deadline-miss as defined as an event when the actual token generation time of the
i thtoken exceedsDi. ‘Note that in the event of a deadline-miss, depending on the length of the stall, many subsequent tokens may miss their deadlines defined as above. This can be misleading as a single stall can amount to 10s of deadline-misses.
To account for this, reset the deadlines for all subsequent tokens is done if there was a deadline-miss at the
s thtoken using the formula below :
Di = ts + (i − s) × Ddwhere ts is the actual generation time of the s th token, and compute the deadline-misses of subsequent tokens based on these refreshed deadlines’ [1].